How I Learned to Stop Worrying and Log the Noise
Living in Berlin means accepting a certain soundtrack. I know what I signed up for when I chose to live on a city artery. Nonetheless I am sensitive to sound, and the constant wail of sirens started to feel… excessive. Was I imagining it? There was only one way to find out… another DIY recording project. I’ve already toyed with some window DIY data projects before, like my air quality sensor. This time we’re gonna learn about noise pollution rather than air pollution.
Berlin has some open data on city noise. My humble 237-meter section of Mehringdamm, as of 2019 (kinda dated), had an average noise level of 75 dB(A) with a staggering 43,140 vehicles passing by daily. To put that in perspective, if you lined those cars up bumper-to-bumper, each averaging 4.5 meters, you’d have a 194-kilometer-long metal snake. No wonder it’s a bit loud.
The recording setup
Nothing fancy here. I used a spare linux laptop from the closet, and just laid it on living room window sill along with the plants. That’s it. Not even a USB microphone. I cranked up the audio input to max, and then thought about how to record the audio and make sense of what comes in.
Making sense of the recorded audio
My first attempt to quantify the sirens involved a Fast Fourier Transform. My thought was to isolate the dominant frequency range of sirens, which are predictable. The Python library SciPy has a built-in FFT function, made bootstrapping this relatively easy. But the FFT proved to be a bit too enthusiastic, generating a lot of false positives. My baby daughter’s crying repeatedly showed up in the siren detection, which, I admit, tugged at the heartstrings a little while combing through the recorded samples. Clearly, a more sophisticated approach was needed.
TensorFlow
I stumbled upon an excellent tutorial in TensorFlow’s documentation for classifying audio using the YAMNet model. This model conveniently includes a subset of sirens in its training data. Perfect!
Processing a live stream turned out not to be possible with TensorFlow though. The solution? Record audio constantly in two-second chunks (enough to capture a full siren cycle), then feed those snippets to the YAMNet model. I also made sure to keep the raw audio recordings for any deeper analysis that might be required later. All detected siren events with timestamps were dutifully logged to a CSV for easy digestion.
Here’s what I ended up with:
import numpy as np
import sounddevice as sd
import tensorflow as tf
import tensorflow_hub as hub
import pandas as pd
import time
import os
from datetime import datetime
from scipy.io import wavfile
import requests
# --- Configuration ---
MODEL_URL = "https://tfhub.dev/google/yamnet/1"
SAMPLE_RATE = 16000 # YAMNet requires 16000 Hz sample rate
BLOCK_DURATION_S = 2.0 # Process audio in 2-second chunks
BLOCK_SIZE = int(SAMPLE_RATE * BLOCK_DURATION_S)
DETECTION_THRESHOLD = 0.55 # Confidence threshold from 0 to 1
SIREN_CLASS_NAME = "Siren"
SIREN_EVENT_CSV = "siren_events.csv"
SIREN_EVENT_INTERVAL = 30 # seconds
SIREN_SAMPLE_DIR = "siren_samples"
last_siren_time = 0
# --- Load YAMNet Model ---
print("Loading YAMNet model...")
model = hub.load(MODEL_URL)
# Load class names from the CSV file referenced by model.class_map_path
class_map_path = model.class_map_path().numpy().decode('utf-8')
class_map_df = pd.read_csv(class_map_path)
class_names = class_map_df['display_name'].values.astype('U')
print("Model loaded.")
# Ensure the sample directory exists
os.makedirs(SIREN_SAMPLE_DIR, exist_ok=True)
def audio_callback(indata, frames, time_info, status):
global last_siren_time
if status:
print(status)
waveform = indata[:, 0].astype(np.float32)
scores, embeddings, spectrogram = model(waveform)
siren_index = np.where(class_names == SIREN_CLASS_NAME)[0][0]
siren_score = tf.reduce_mean(scores[:, siren_index]).numpy()
now = time.time()
if siren_score > DETECTION_THRESHOLD and (now - last_siren_time) >= SIREN_EVENT_INTERVAL:
last_siren_time = now
timestamp = datetime.now().isoformat()
print(f"🚨 SIREN DETECTED! (Confidence: {siren_score:.2f}) at {timestamp}")
# Save WAV sample
wav_filename = f'siren_{datetime.now().strftime("%Y%m%d_%H%M%S")}.wav'
wav_path = os.path.join(SIREN_SAMPLE_DIR, wav_filename)
# Convert waveform to int16 for WAV
wav_data = np.int16(waveform / np.max(np.abs(waveform)) * 32767) if np.max(np.abs(waveform)) > 0 else np.int16(waveform)
wavfile.write(wav_path, SAMPLE_RATE, wav_data)
# Append to CSV
if not os.path.exists(SIREN_EVENT_CSV):
with open(SIREN_EVENT_CSV, 'w') as f:
f.write('timestamp,wav_filename\n')
with open(SIREN_EVENT_CSV, 'a') as f:
f.write(f'{timestamp},{wav_path}\n')
# --- Main Execution ---
try:
print("\nListening for sirens... Press Ctrl+C to stop.")
# Start the audio stream
with sd.InputStream(
channels=1,
samplerate=SAMPLE_RATE,
blocksize=BLOCK_SIZE,
callback=audio_callback
):
while True:
pass # Keep the stream alive
except KeyboardInterrupt:
print("\nStopping...")
except Exception as e:
print(f"An error occurred: {e}")I let the model run for a month on my little linux laptop, and here’s the result.
At first glace, yeah, that’s a lot of sirens. I’m not crazy! Also interesting that the number of siren events per day varies widely in the beginning, and then the curve kind of stabilizes toward the end. I guess that’s just how convergence and increasing sample size works.
The first day (July 26th) was also abnormally high, I think because it happened to be Christopher Street Day, a yearly pride parade in Berlin.
👮♂️ Police siren
Looking at this audio sample in Audacity with the spectrogram view, it’s clear that it’s a police siren. The harmonics are quite distinct, and the overall shape is quite regular.
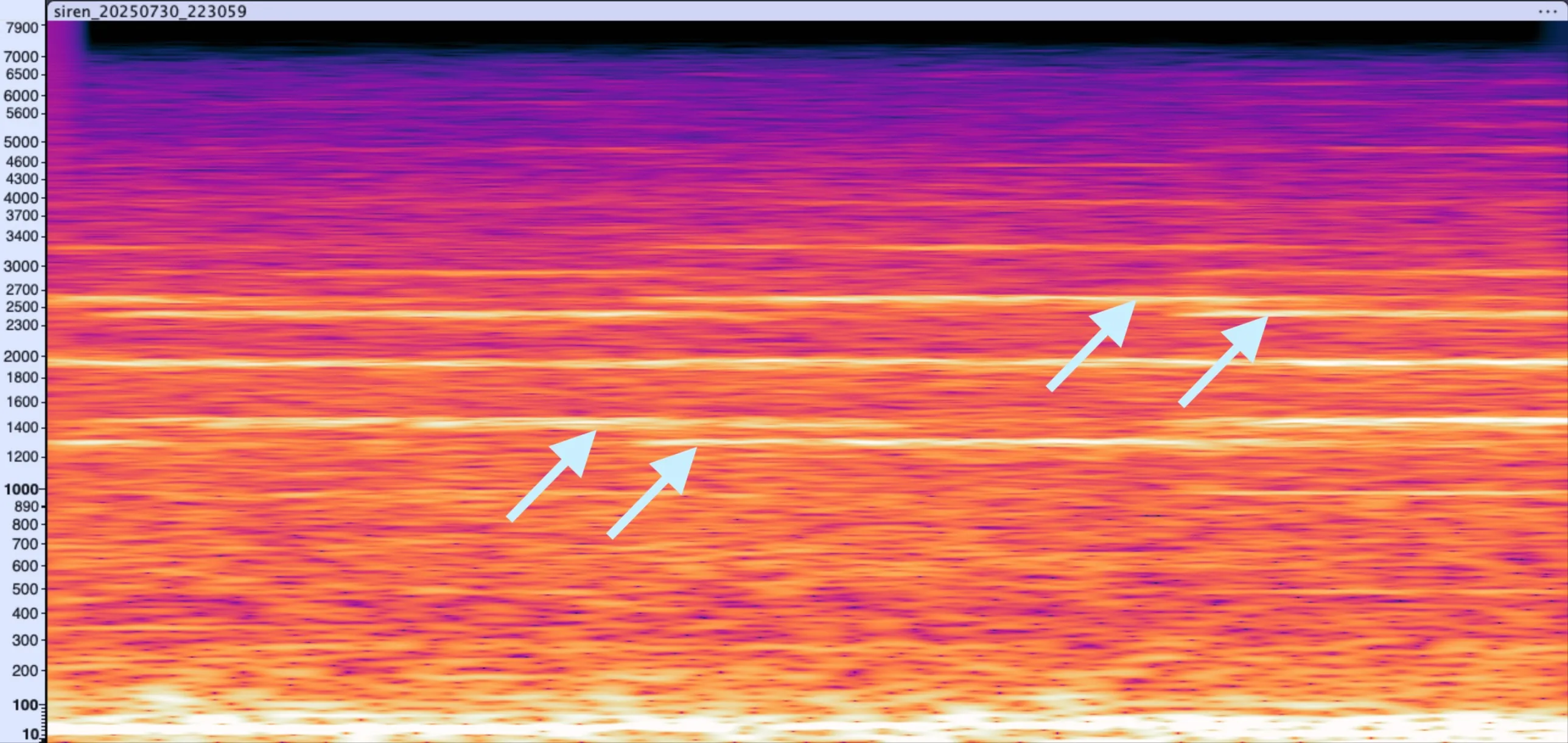
Notice how the harmonics are clean multiples of the fundamental frequency, just appearing a little weaker in the spectrum. Pretty cool!
🚑 Ambulance siren
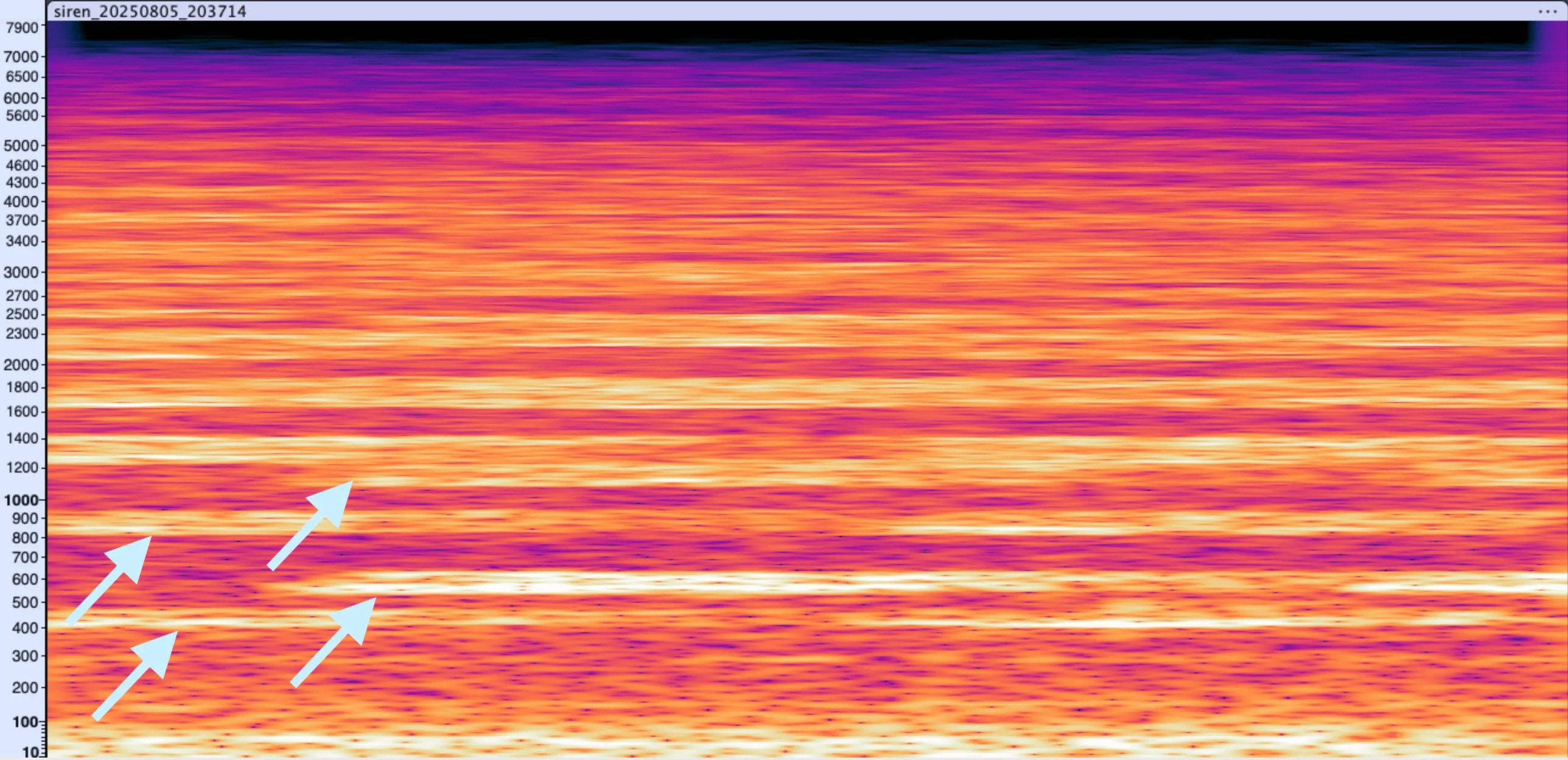
Lower fundamental frequency here for ambulance sirens is interesting. I learned that these lower frequencies carry better in the dense urban environment, but also, wow, they are freaking loud too. 130 dB(A) is at the human pain threshold.
Wrapping up
This was a fun project, and I learned a lot about noise pollution and sirens. Also vibe-coded enough Python to make it work. Would be cool to also auto-classify the sirens according to vehicle type, but that wasn’t my original goal.